On December 5, 2024, Google announced “PaliGemma 2”, a visual language model that adds visual functions based on the open and lightweight language model “Gemma 2”.
Introducing PaliGemma 2: Powerful Vision-Language Models, Simple Fine-Tuning – Google Developers Blog
https://developers.googleblog.com/en/introducing-paligemma-2-powerful-vision-language-models-simple-fine-tuning/
Welcome PaliGemma 2 – New vision language models by Google
https://huggingface.co/blog/paligemma2
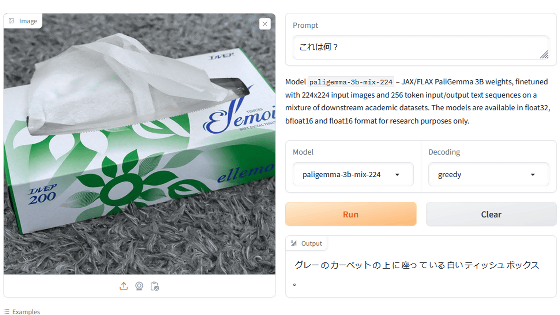
PaliGemma is the first visual language model in the Gemma family.GitHuborHugging FaceIt has the ability to recognize images, verbally describe the content of the image, and understand the text within the image.
If you read the article below, you will see what happens when you actually use PaliGemma.
Google releases open source visual language model “PaliGemma” & announces large-scale language model “Gemma 2” with performance equivalent to Llama 3 – GIGAZINE
Now released, its successor, PaliGemma 2, is available in multiple model sizes (3B, 10B, 28B) and resolutions (224×224, 448×448, 896×896 pixels) to optimize performance for any task. will become.
Another selling point is the length of the captions, which go beyond simply recognizing objects to generating detailed, contextual captions that can describe movement, emotion, and the context of an entire scene, or even chemical formulas or musical scores. It is said that it can show excellent performance in recognition, spatial reasoning, and chest X-ray image reporting.
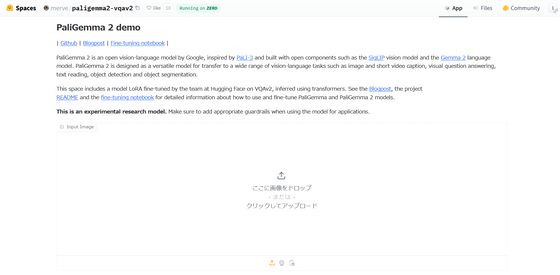
A demo site is also available.
Paligemma2 Vqav2 – a Hugging Face Space by merve
https://huggingface.co/spaces/merve/paligemma2-vqav2
As a test, let’s click on the sample that asks you what type of graph it is.
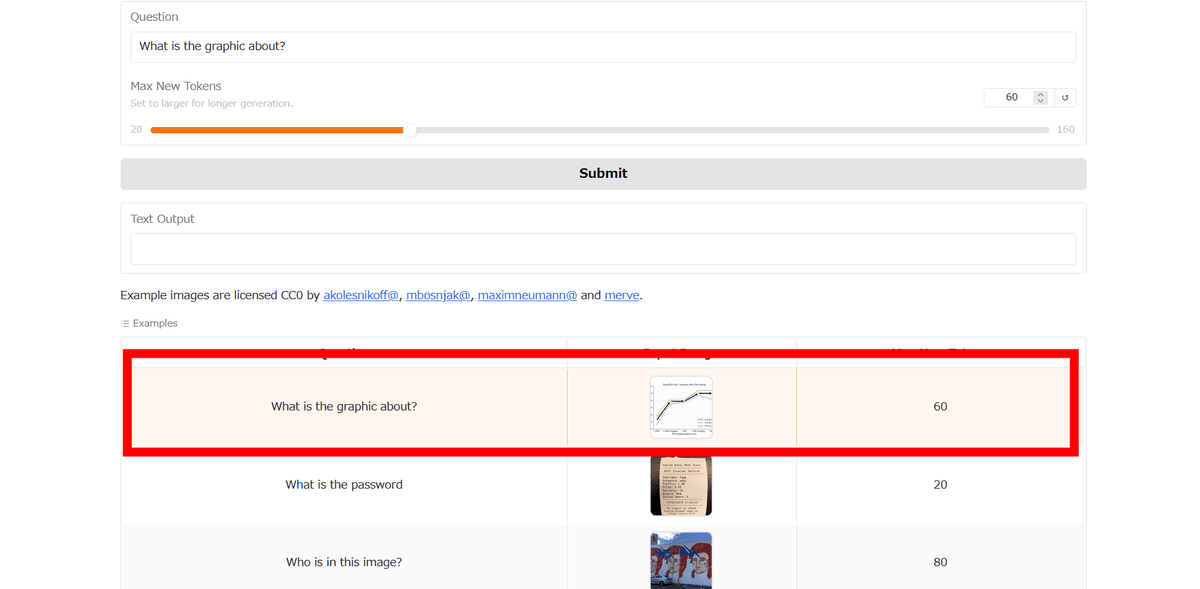
The model then answered, “Accuracy after fine tuning.”
Google says, “We can’t wait to see what you create with PaliGemma 2. Join the vibrant Gemma community, share your projects on Gemmaverse, and let’s continue exploring the endless possibilities of AI together.” ” he said.
Copy the title and URL of this article