It supports over 30 languages and also has audio that can read sentences in multiple voices and accents.Play 3.0 mini‘ has appeared. It also supports Japanese, and the selling point is the “naturalness of the voice.”
Introducing Play 3.0 Mini – A Lightweight, Reliable And Cost-efficient Multilingual Text-to-Speech Model
https://play.ht/news/introducing-play-3-0-mini/
You can try “Play 3.0 mini” for free by registering your email address or Google account from the page below.
PlayAI Text-to-Speech API Playground
https://play.ht/playground/
I want to try it in Japanese, so when I access it, I change “LANGUAGE” to “Japanese”.
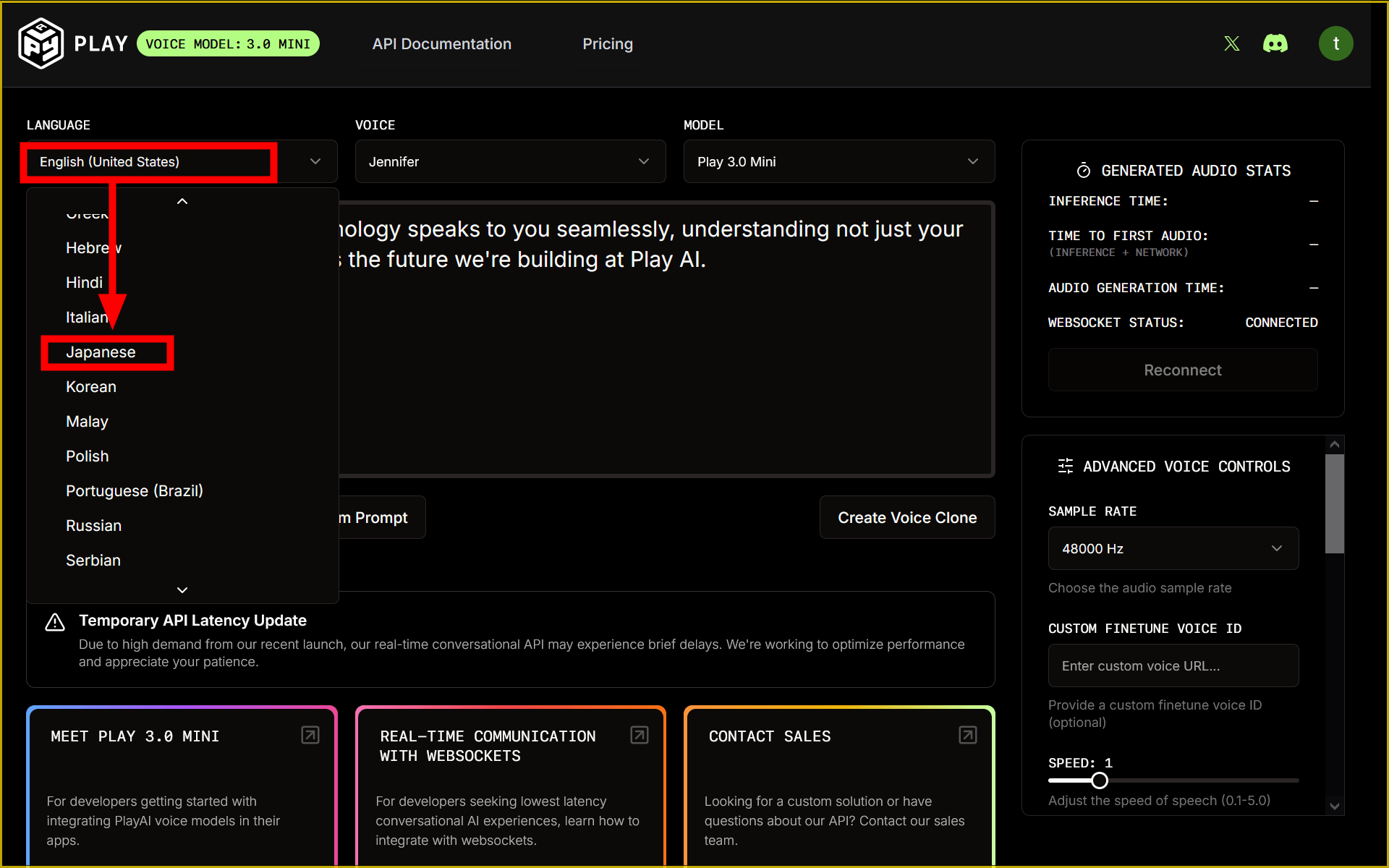
Select your favorite voice from “VOICE”.
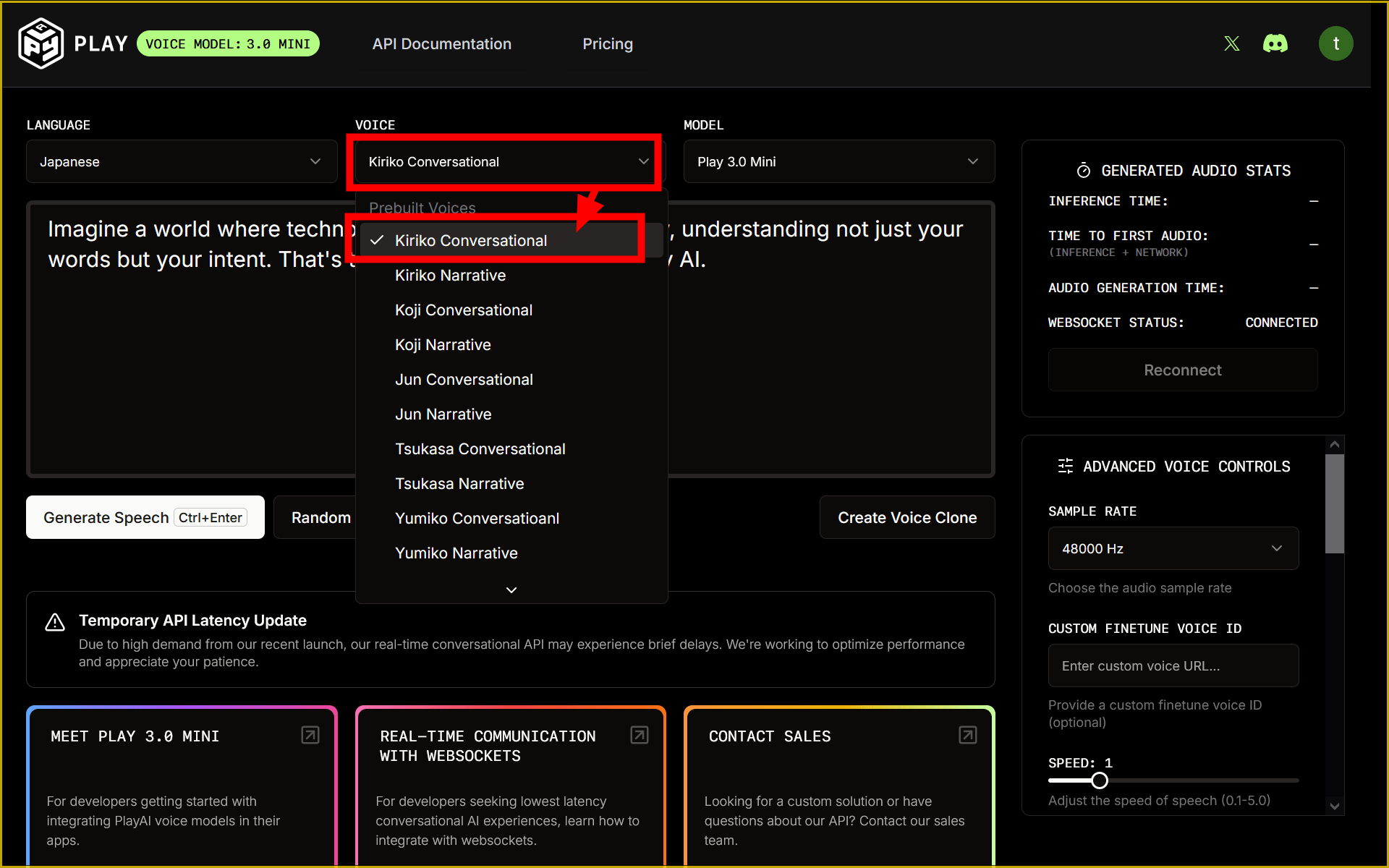
Enter the text in the input box and click “Generate Speech” to generate speech.
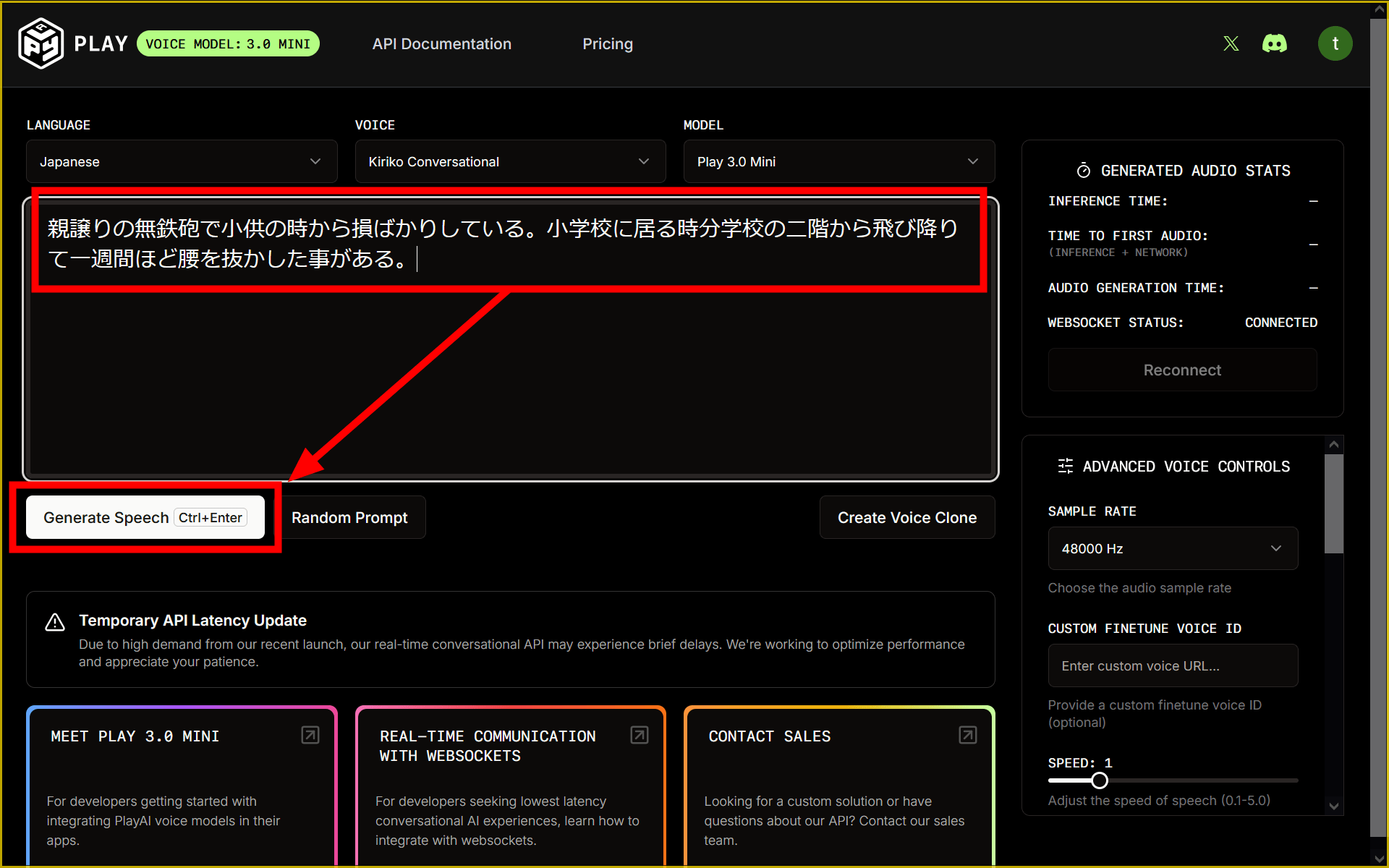
I tried having the text read out loud with several voices. Although it does read aloud with a natural accent, I am concerned that the audio is interrupted and some words are not pronounced properly. The average waiting time for generation speed is 189 milliseconds.
I tried “Play 3.0 mini” which can read sentences with male/female voice – YouTube

“Play 3.0 mini” supports over 30 languages including Japanese, Hindi, Arabic, Spanish, Italian, German, and French, and in addition to the trial sites listed above.APIAvailable through. By building applications using APIs, you can create conversational models that respond to user feedback.
Introducing Play 3.0 mini – a new compact Text to Speech model for realtime Voice AI – YouTube

Please note that some API usage is free, but basicallyFeeIt takes.
According to the developer, PlayHT, “hallucinations” can be seen in speech large-scale language models, just as in conversational large-scale language models, and most text-to-speech models are prone to misread alphanumeric characters. thing. Play 3.0 mini has adjusted this point and is compatible with use cases where it would be a problem if important information such as phone numbers, passport numbers, dates, etc. were misread.
PlayHT says, “Play3.0mini is the fastest and most conversational voice model, while significantly improving reliability and sound quality. An efficient multilingual AI voice synthesis model that we plan to release in the coming months. “Our goal is to make the model small and cost-effective so it can run on users’ devices.”
Copy the title and URL of this article